Dictionary в .NET


В этой статье рассматриваем какие типы Dictionary бывают в C# и смотрим под капот и более глубоко по работе с ними. Частично Dictionary и другие коллекции мы затрагивали в этой статье.
Оглавление:
- Dictionary
- ListDictionary
- HybridDictionary
- OrderedDictionary
- SortedDictionary
- StringDictionary
- ConcurrentDictionary
- ImmutableDictionary и ReadOnlyDictionary
Dictionary
Словарь (dictionary) — это обобщенная версия Hashtable содержащая в себе объект структуры KeyValuePair<TKey, TValue>. Главное свойство dictionary— быстрый поиск с помощью ключей. Можно также добавлять и удалять элементы, наподобие того как это делается в List<T>, но без расходов производительности, связанных с необходимостью смещения последующих элементов в памяти.
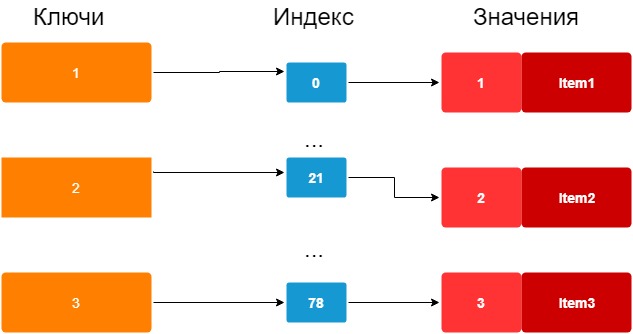
На диаграмме ниже вы можете увидеть упрощенную модель dictionary. Здесь ключами словаря служат ID, такие, как: 1,2,3. Ключ в последствии трансформируется в хэш. В хэше создается число для ассоциации индекса с Value. После этого индекс содержит ссылку на Value.
Требования к ключу Dictionary
Dictionary использует метод GetHashCode() класса Object для вычисления целого числа которое используется для поиска индекса для вставки нового значения.
Реализовывая свой кастомный GetHashCode() вы должны удовлетворить следующие требования:
-
Один и тот же объект должен всегда возвращать одинаковый хэш-код (Хэш-код не должен изменятся во время жизни объекта).
-
Разные объекты могут возвращать одно и то же значение хэш-кода.
-
Метод должен выполняться очень быстро.
-
Он не должен генерировать эксепшенов.
-
Он должен использовать как минимум одно поле экземпляра.
-
Значения хэш-кода должны распределяться равномерно по всему диапазону чисел, которые может хранить int.
Зачем равномерно распределять значения хэш-кода по диапазону целых чисел?
Если два ключа возвращают хэш-значения, дающие один и тот же индекс, Dictionary приходится искать ближайшее доступное свободное место для сохранения второго элемента, к тому же ему придется выполнять некоторый поиск, чтобы впоследствии извлечь требуемое значение. Это сильно влияет на производительность, Microsoft, разработала хороший алгоритм который вычисляет значение хэш-кода равномерно распределено между int.MinValue и int.MaxValue. Следовательно, это снижает угрозу с производительностью Dictionary, а значит всегда старайтесь использовать стандартный метод GetHashCode от Майкрософт. Более детально про Equals можно почитать в этой статье.
Поскольку разные объекты ключа могут возвращать один и тот же хэш-код, метод Equals() используется при сравнении ключей словаря. Словарь проверяет два ключа А и В на эквивалентность, вызывая A.Equals(В)
Insert
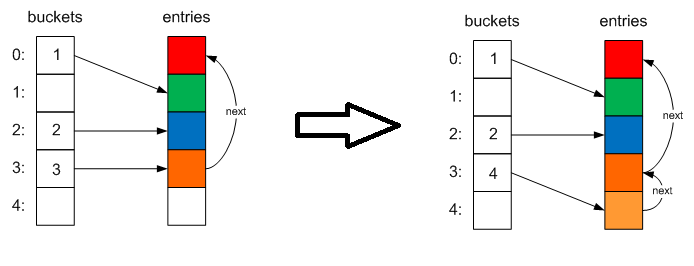
Если мы обратимся к исходному коду словаря, то у видим что словаря есть один очень важный field private int[] buckets; который используется в словаре для быстрой вставки и поиска значений в словаре.
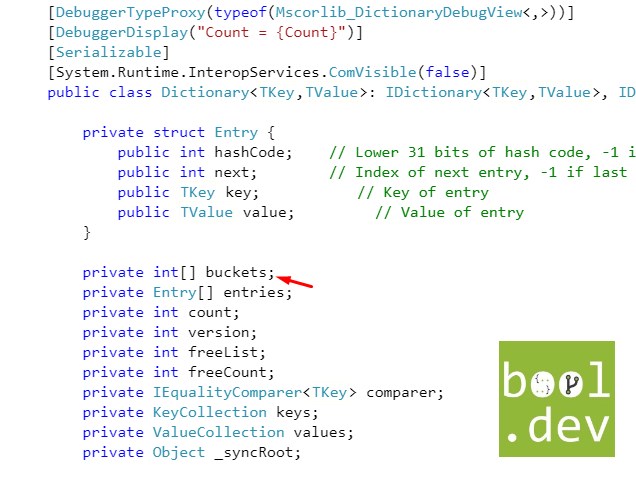
Рассмотрим подробнее как происходит вставка нового значения в Dictionary:
При добавлении элемента вычисляется хэш-код Key объекта и формируется значение currentBucket'a на основании этого хэш-кода
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
int targetBucket = hashCode % buckets.Length;
В конце присваиваются значения новосозданному объекту
entries[index].hashCode = hashCode;
entries[index].next = buckets[targetBucket];
entries[index].key = key;
entries[index].value = value;
buckets[targetBucket] = index;
version++;
Схематически это будет Выглядить следующим образом:
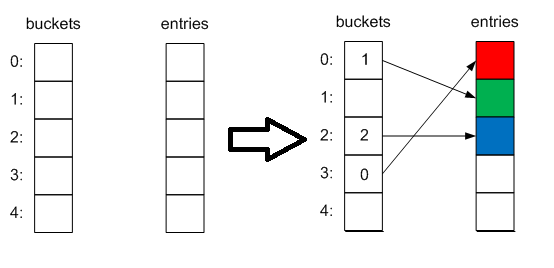
Если в buckets уже есть элемент с bucketNum, новый элемент добавляется в коллекцию, а индекс сохраняется в buckets, а индекс старого элемента в его поле next, сематически это выглядит вот так:
Remove
Удаление со словаря представлено следующим кодом:
public bool Remove(TKey key)
{
if (key == null)
{
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (buckets != null)
{
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
int bucket = hashCode % buckets.Length;
int last = -1;
for (int i = buckets[bucket]; i >= 0; last = i, i = entries[i].next)
{
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key))
{
if (last < 0)
{
buckets[bucket] = entries[i].next;
}
else
{
entries[last].next = entries[i].next;
}
entries[i].hashCode = -1;
entries[i].next = freeList;
entries[i].key = default(TKey);
entries[i].value = default(TValue);
freeList = i;
freeCount++;
version++;
return true;
}
}
}
return false;
}
Как мы видим при удаленимы удаляем содержимое ячеек значениями по умолчанию, меняем указатели next других элементов при неоходимости и сохраняем индекс этого элемента во внутреннее поле freeList, а старое в поле next. Таким образом, при добавлении нового элемента мы можем повторно использовать такие свободные ячейки:
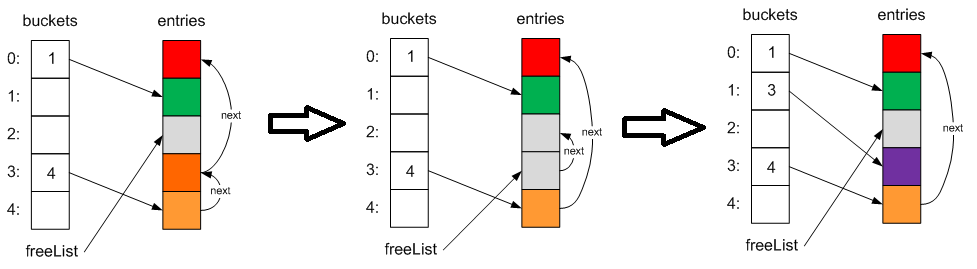
Помните, что при очистке Dictionary, (метод Clear) его внутренний размер не изменяется. То есть, потенциально, вы можете тратить место.
Исходя из того что мы узнали давайте рассмотрим несколько примеров что я написал.
Первый пример когда в качестве ключа служит структура (для наглядности примера я переопределил метод GetHashCode который теперь всегда будет возвращать 0):
class Program
{
static void Main(string[] args)
{
var dictionary = new Dictionary<MyStruct, string>();
var str = new MyStruct
{
Value = 1
};
var str2 = new MyStruct
{
Value = 2
};
dictionary[str] = "record 1";
dictionary[str2] = "record 2";
str.Value = 3;
dictionary[str] = "record 3";
foreach (var pair in dictionary)
{
Console.WriteLine($"{pair.Key} {pair.Value}");
}
Console.ReadKey();
}
}
struct MyStruct
{
public int Value { get; set; }
public override int GetHashCode()
{
return 0;
}
}
Что будет выведено в результате на экран?
console.MyStruct record 1
console.MyStruct record 2
console.MyStruct record 3
Мы получим 3 записи, почему?
Давайте вспомним как работает Equals в структурах. Он сравнив значения всех свойств увидел что несмотря на то что str не менялась, а только изменилась str.Value определил что это другая структура и записал ее новым элементом словаря.
Теперь давайте рассмотрим другой пример, когда в качестве ключа используется класс:
class Program
{
static void Main(string[] args)
{
var dictionary = new Dictionary<MyClass, string>();
var str = new MyClass
{
Value = 1
};
var str2 = new MyClass
{
Value = 2
};
dictionary[str] = "record 1";
dictionary[str2] = "record 2";
str.Value = 3;
dictionary[str] = "record 3";
foreach (var pair in dictionary)
{
Console.WriteLine($"{pair.Key} {pair.Value}");
}
Console.ReadKey();
}
}
class MyClass
{
public int Value { get; set; }
public override int GetHashCode()
{
return 0;
}
}
В этот раз очевидно будет выведено всего 2 записи
console.MyClass record 3
console.MyClass record 2
Почему так произошло?
Класс это ссылочный тип, следовательно тот факт что мы изменили Value в классе, никак не влияет при его проверке методом Equals
ListDictionary
Это простая реализация IDictionary с использованием односвязного списка. Она меньше и быстрее, чем Hashtable, если количество элементов равно 10 или меньше. Лучше не использовать этот класс, если вам важна производительность для большого количества элементов.
Принимает в качестве параметров тип Object.
Пример инициализации:
var dictionary = new ListDictionary
{
{ "key", "value"}
};
HybridDictionary
Гибридная версия между ListDictionary и HashTable. До 10 элементов гибрит использует ListDictionary элементов если же коллекция становится больше чем 10 элементов, он переключается на работу с HashTable
OrderedDictionary
Иногда бывают моменты когда вы хотите использовать ключи для поиска или foreach для итерации с помощью DictionaryEntry объектов. Элементы OrderedDictionary доступны с помощью ключа или индекса .Элементы OrderedDictionary не сортируются по ключу, в отличие от элементов SortedDictionary<TKey,TValue> класса который мы рассматриваем выше.
static void Main(string[] args)
{
var dictionary = new OrderedDictionary
{
{"01", "odin"},
{"02", "dva"},
{"03", "tri"},
{"04", "chetiri"},
{"05", "pyat"}
};
// Reference the values array style
for (int i = 0; i < dictionary.Count; i++)
{
string valueString = (string)dictionary[i];
Console.WriteLine(valueString);
}
// Reference the values Dictionary style
foreach (DictionaryEntry myDE in dictionary)
{
Console.WriteLine(myDE.Value);
}
Console.ReadKey();
}
Вы можете видеть, что я использовал два разных метода, чтобы перебрать коллекцию. В первом примере я использовал цикл for и числовой индекс для извлечения каждого объекта (в данном случае строки), хранящегося в коллекции.
Другим преимуществом OrderedDictionary является скорость. При просмотре большой коллекции чтение OrderedDictionary с использованием первого примера, числового индекса, всегда будет быстрее, чем при использовании метода стиля словаря.
Когда вам нужна "мощь" коллекции и простой доступ к числовому индексу, OrderedDictionary является предпочтительной коллекцией.
SortedDictionary
Класс SortedDictionary<TKey, Tvalue> представляет дерево бинарного поиска, в котором все элементы отсортированы на основе ключа. Тип ключа должен реализовать интерфейс IComparable<TKey>. Если тип ключа не сортируемый, компаратор можно также создать, реализовав IComparer<TKey> и указав его в качестве аргумента конструктора сортированного словаря.
Классы SortedDictionary<TKey, Tvalue> и SortedList<TKey, TValue> часто сравнивают друг с другом, так как они имеют схожий функционал. Но поскольку SortedList<TKey, TValue> реализован в виде списка, основанного на массиве, a SortedDictionary<TKey, Tvalue> реализован как словарь, эти классы обладают разными характеристиками:
- SortedList<TKey, TValue> использует меньше памяти, чем SortedDictionary<TKey, TValue>
-
SortedDictionary<TKey, TValue> быстрее вставляет и удаляет элементы.
-
При наполнении коллекции отсортированными данными SortedList<TKey,TValue> работает быстрее, если при этом не требуется изменение размера.
Класс SortedDictionary<TKey, TValue> реализует интерфейсы IDictionary, IDictionary<TKey, TValue>, ICollection, ICollection<KeyValuePair<TKey, TValue>>, IEnumerable и IEnumerable<KeyValuePair<TKey, TValue>>. В классе SortedDictionary<TKey, TValue> реализованы следующие конструкторы:
public SortedDictionary()
public SortedDictionary(IDictionary<TKey, TValue> dictionary)
public SortedDictionary(IComparer<TKey> comparer)
public SortedDictionary(IDictionary<TKey, TValue> dictionary, IComparer<TKey> comparer)
В первом конструкторе создается пустой словарь, во втором конструкторе — словарь с указанным количеством элементов dictionary. В третьем конструкторе допускается указывать с помощью параметра comparer типа IComparer способ сравнения, используемый для сортировки, а в четвертом конструкторе — инициализировать словарь, помимо указания способа сравнения.
В классе SortedDictionary<TKey, TValue> определен ряд методов. Некоторые наиболее часто используемые методы этого класса приведены ниже:
Add()
Добавляет в словарь пару "ключ-значение", определяемую параметрами key и value. Если ключ key уже находится в словаре, то его значение не изменяется, и генерируется исключение ArgumentException
ContainsKey()
Возвращает логическое значение true, если вызывающий словарь содержит объект key в качестве ключа; в противном случае — логическое значение false
ContainsValue()
Возвращает логическое значение true, если вызывающий словарь содержит значение value, в противном случае — логическое значение false
Remove()
Удаляет ключ key из словаря. При удачном исходе операции возвращается логическое значение true, а если ключ key отсутствует в словаре — логическое значение false
Следует иметь в виду, что ключи и значения, содержащиеся в коллекции, доступны отдельными списками с помощью свойств Keys и Values. В коллекциях типа SortedDictionary<TKey, TValue>.KeyCollection и SortedDictionary<TKey, TValue>.ValueCollection реализуются как обобщенные, так и необобщенные формы интерфейсов ICollection и IEnumerable.
StringDictionary
Предназначен для хеш-таблиц, в которых хранятся пары "ключ-значение", причем и ключ, и значение относятся к типу string. На данный момент этот класс является устрашевшим и не рекомендую вам его использовать в ваших приложениях.
ConcurrentDictionary
Представляет потокобезопасную коллекцию пар "ключ-значение", доступ к которой могут одновременно получать несколько потоков.
Для настройки есть 2 основных параметра:
сapacity — первоначальное кол-во элементов. По умолчанию — 31.
concurrencyLevel – предполагаемое число потоков на запись. По умолчанию = 4
Методы ConcurrentDictionary.
Основные Методы словаря можно разделить на 3 группы:
- полностью неблокируемые;
- блокировка одного элемента из пула блокировок;
- блокировка всего словаря;
К полностью не блокируемым операциям можно отнести:
- ContainsKey
- TryGet
- this [ ]
- GetEnumerator – операция не обеспечивает целостность данных (не использует снепшоты), т.е. данные за время работы функции могут поменяться.
Все операции чтения (Get/ContainsKey) имеют примерно одинаковый алгоритм работы:
- вычисление хеша ключа через GetHashCode()
- вычисление бакета, в котором лежит наш элемент
- сравнения значения ключа в бакете с тем, который у нас
- чтение значения с использованием Volatile.Read
К операциям с блокировкой одного элемента из пула блокировок можно отнести:
- TryAdd
- TryUpdate
- TryRemove
Ниже примерный алгоритм работы:
- Вычисление хеша ключа нового элемента
- Вычисление бакета bucketNo, в который будет добавлен элемент, и номера блокировки из пула
- Блокировка bucketNo через Monitor.Enter
- Запись элемента с использованием Volatile.Write
- Освобождение блокировки Monitor.Exit
К самым неэффективным операциям, которые блокируют весь словарь, относятся:
- Count, IsEmpty. Да, эти операции требуют полной блокировки словаря. Если вам необходимо сохранить в лог-файл число элементов, то можно использовать GetEnumerator и LINQ. Так же эти методы захватывают все локи в словаре. Лучше воздержаться от частого вызова этих свойств из нескольких потоков.
- Keys, Values – получение списка ключей и списка значений соответственно. Они не только берут все локи, но и целиком копируют в отдельный List все ключи и значения. В отличие от традиционного Dictionary, одноимённые свойства которого возвращают «тонкие» обертки, здесь нужно быть готовым к крупным аллокациям памяти.
- CopyTo – explicit ICollection
- Clear, ToArray
В отличие от обычного Dictionary, можно производить вставку в ConcurrentDictionary или удаление из него прямо во время перечисления
foreach (var pair in dictionary)
{
if (IsStale(pair.Value))
{
dictionary.TryRemove(pair.Key, out _);
}
}
Удалять элементы можно не только по ключу, но и по точному совпадению key + value, причем атомарно! Это недокументированная возможность, скрытая за explicit-реализацией интерфейса ICollection. Она позволяет безопасно очищать такой кэш даже в условиях гонки с обновлением значения:
var collection = cache as ICollection<KeyValuePair<MyKey, MyValue>>
foreach (var pair in cache)
{
if (IsStale(pair.Value))
{
// Remove() will return false in case of race with value update
var removed = collection.Remove(pair);
}
}
в условиях конкурентного доступа GetOrAdd может вызвать делегат-фабрику для одного ключа сильно больше одного раза. Если так делать нельзя или дорого, достаточно обернуть значение в Lazy:
var dictionary = new ConcurrentDictionary<MyKey, Lazy<MyValue>>();
var lazyMode = LazyThreadSafetyMode.ExecutionAndPublication;
var value = dictionary
.GetOrAdd(key, _ => new Lazy<MyValue>(() => new MyValue(), lazyMode))
.Value;
ImmutableDictionary и ReadOnlyDictionary
ReadOnlyDictionary можно инициализировать всего один раз через конструктор, После вы не сможете добавлять или удалять в него элементы. Это полезно, если вы хотите убедиться, что он не будет изменен, пока он будет отправлен через несколько уровней вашего приложения. Вы инициализируете ReadOnlyDictionary, передавая другой экземпляр слова конструктору. Это объясняет, почему ReadOnlyDictionary является изменяемым (если базовый словарь изменен). Это просто оболочка, защищенная от прямых изменений.
В ImmutableDictionary есть методы для его модификации, такие как " Add или " Remove, но они создадут новый словарь и вернут его, исходный останется без изменений и вернется копия нового неизменяемого словаря. ImmutableDictionary является потокобезопасным, потому что вы не можете изменить исходный экземпляр (ни прямо, ни косвенно). Все методы, которые "изменяют", фактически возвращают новый экземпляр.
Бенчмарки и итоги
Теперь давайте сравним быстродействие этих листов. ListDictionary исключен из тестов т.к он не эффективен для большого количества записей.
Тестирование проводили с 100000 записями, Код тестирования:
private static void AddItems<T>(T dictionary) where T : IDictionary<int, int>
{
var watch = Stopwatch.StartNew();
for (int i = 0; i < 100000; i++)
{
dictionary.Add(i, i);
}
watch.Stop();
Console.WriteLine(typeof(T) + " Insert operation: " + watch.ElapsedMilliseconds);
watch.Restart();
for (int i = 0; i < 100000; i++)
{
var item = dictionary[i];
}
watch.Stop();
Console.WriteLine(typeof(T) + "Foreach operation: " + watch.ElapsedMilliseconds);
watch.Restart();
for (int i = 0; i < 100000; i++)
{
dictionary[i] = Int32.MaxValue;
}
watch.Stop();
Console.WriteLine(typeof(T) + "Update operation: " + watch.ElapsedMilliseconds);
watch.Restart();
for (int i = 0; i < 100000; i++)
{
dictionary.Remove(dictionary[i]);
}
watch.Stop();
Console.WriteLine(typeof(T) + "remove operation: " + watch.ElapsedMilliseconds);
}
Первый тест на 100к записях:
| Тип | Операция Insert | Операция Foreach | Операция Update | Операция Remove |
|---|---|---|---|---|
| Dictionary | 5мс | 1мс | 1мс | 2мс |
| ConcurrentDictionary | 37мс | 3мс | 8мс | 10мс |
| HybridDictionary | 15мс | 23мс | 10мс | 26мс |
| SortedDictionary | 50мс | 30мс | 26мс | 69мс |
| OrderedDictionary | 55мс | 10мс | 89990мс | 190522мс |
Видим что OrderedDictionary безнадежно проигрывает по сравнению с остальными при обновлении и удалении.
Давайте проведем те же тесты но на 10М записей но уже без OrderedDictionary
| Тип | Операция Insert | Операция Foreach | Операция Update | Операция Remove |
|---|---|---|---|---|
| Dictionary | 491мс | 168мс | 178мс | 275мс |
| ConcurrentDictionary | 4652мс | 239мс | 548мс | 635мс |
| HybridDictionary | 2666мс | 594мс | 2835мс | 1097мс |
| SortedDictionary | 5829мс | 2889мс | 2797мс | 8700мс |
Если сравнить Dictionary с листом, то лист будет проигровать скорости вставки, поиска и удаления.
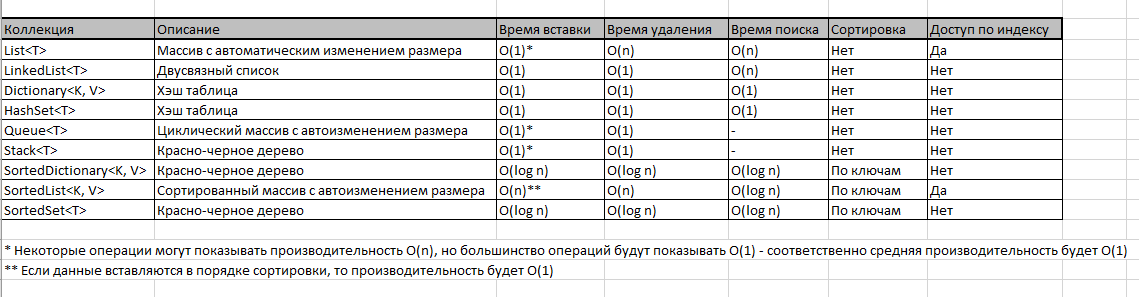
Обратите внимание на таблицу ниже, тут отображены скорость работы методов основных типов коллекций: